
Building Off-chain dApps with ChainSyncer
how to index blockchain data more flexible way than TheGraph can offer


The core idea of Web3 is based on decentralized data storage. Ideally, all your data could be stored in a decentralized manner, but that’s not possible — storing all data like this would be extremely expensive (at least nowadays). Instead, it’s advisable to use decentralized storage for only the most important data.
Where to store the rest of the data, then? — Off-chain. That is, on your backend.
With this approach, you get something like an onion: the most important data is stored securely in the blockchain (on-chain), while less important data is molded around this skeleton as an outer shell.
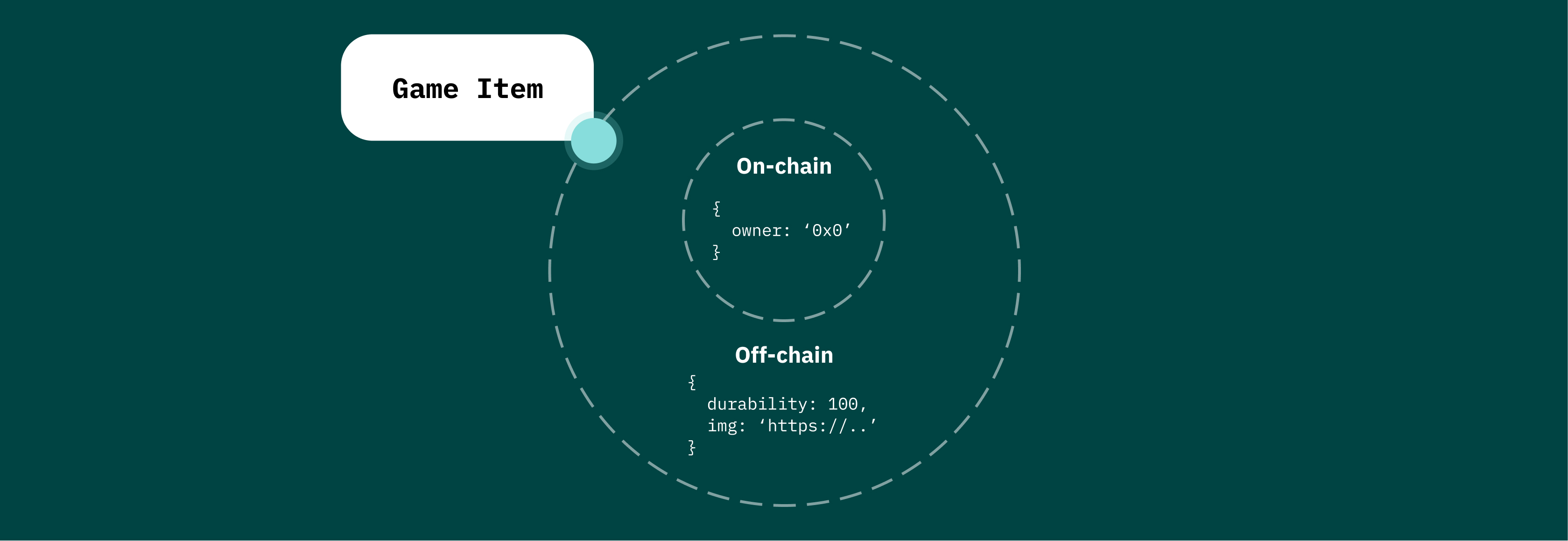
But this way of storing data greatly complicates the application, since in fact the data of one entity is often divided into two databases.
I’ll give you an example. You have an item that stores its owner on-chain, and stores its metadata off-chain. How can the end client get the whole object with the owner and metadata?
There are several options for solving this problem:
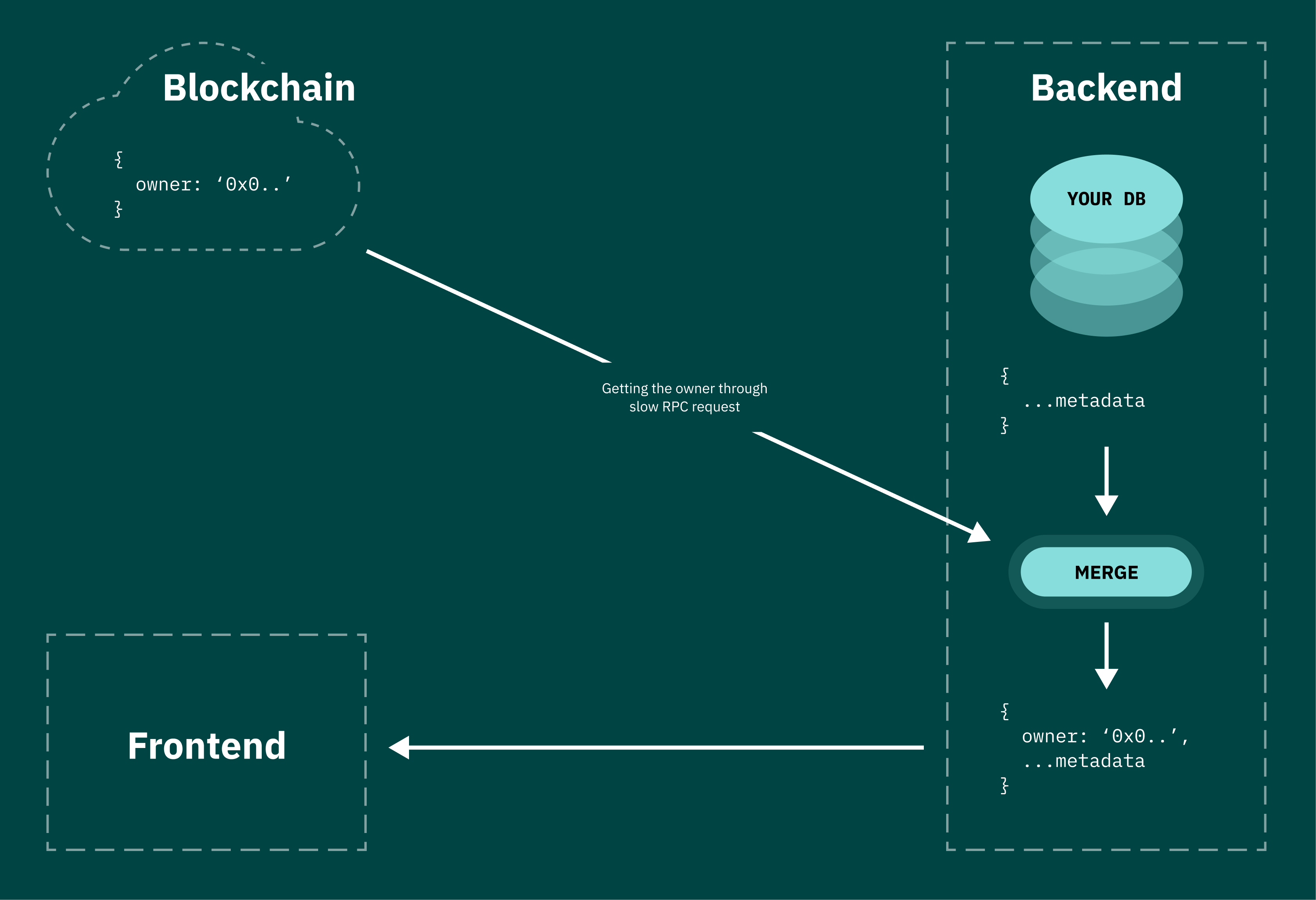
- The first option is to make an endpoint on the backend that makes a request to the RPC server to receive an on-chain object, and then attaches its metadata to it with data from the database. This option is developed quickly, but has a lot of shortcomings that present themselves quickly, too. Namely, RPC requests are extremely slow and inefficient, so the UX of the entire application will suffer. Additionally, most RPC providers (even paid ones) have rather low rate limits, so as the application grows, you’ll quickly run into them.
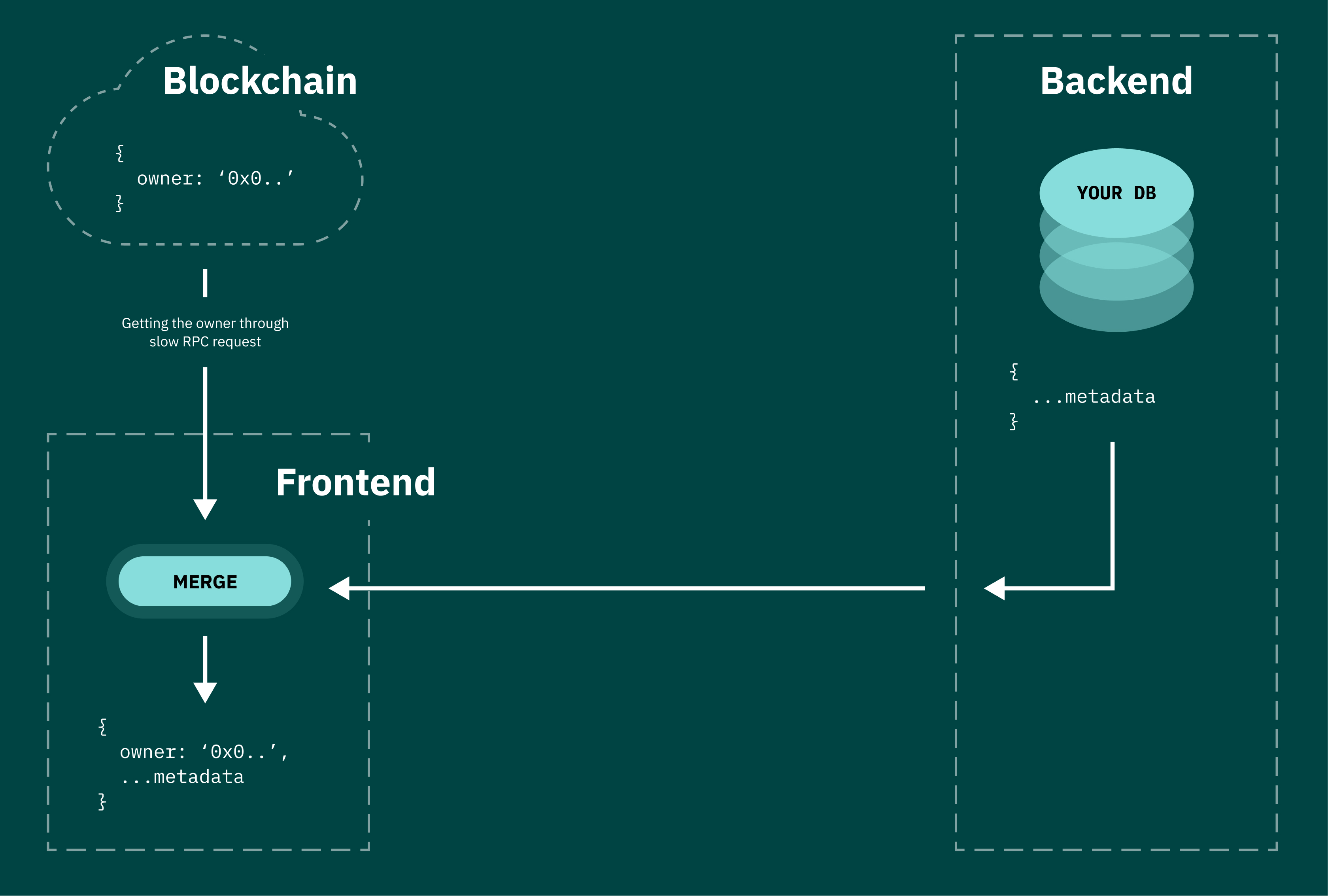
- The second option is to transfer the assembly of the object to the client’s side. The client makes an RPC request to get the owner, then makes a request to your API to get the metadata. The obvious advantage here, compared to the first option, is that you aren’t bottlenecked by rate limits. Among the disadvantages — this option greatly complicates your frontend, and still doesn’t solve the performance problem due to the fact that almost all users use extremely low-quality RPC servers. These servers are known to crash from time to time or freeze indefinitely (especially for BSC). Moreover, this method deprives you of the possibility of a centralized and convenient items search or filtering (for example, searching in the marketplace).
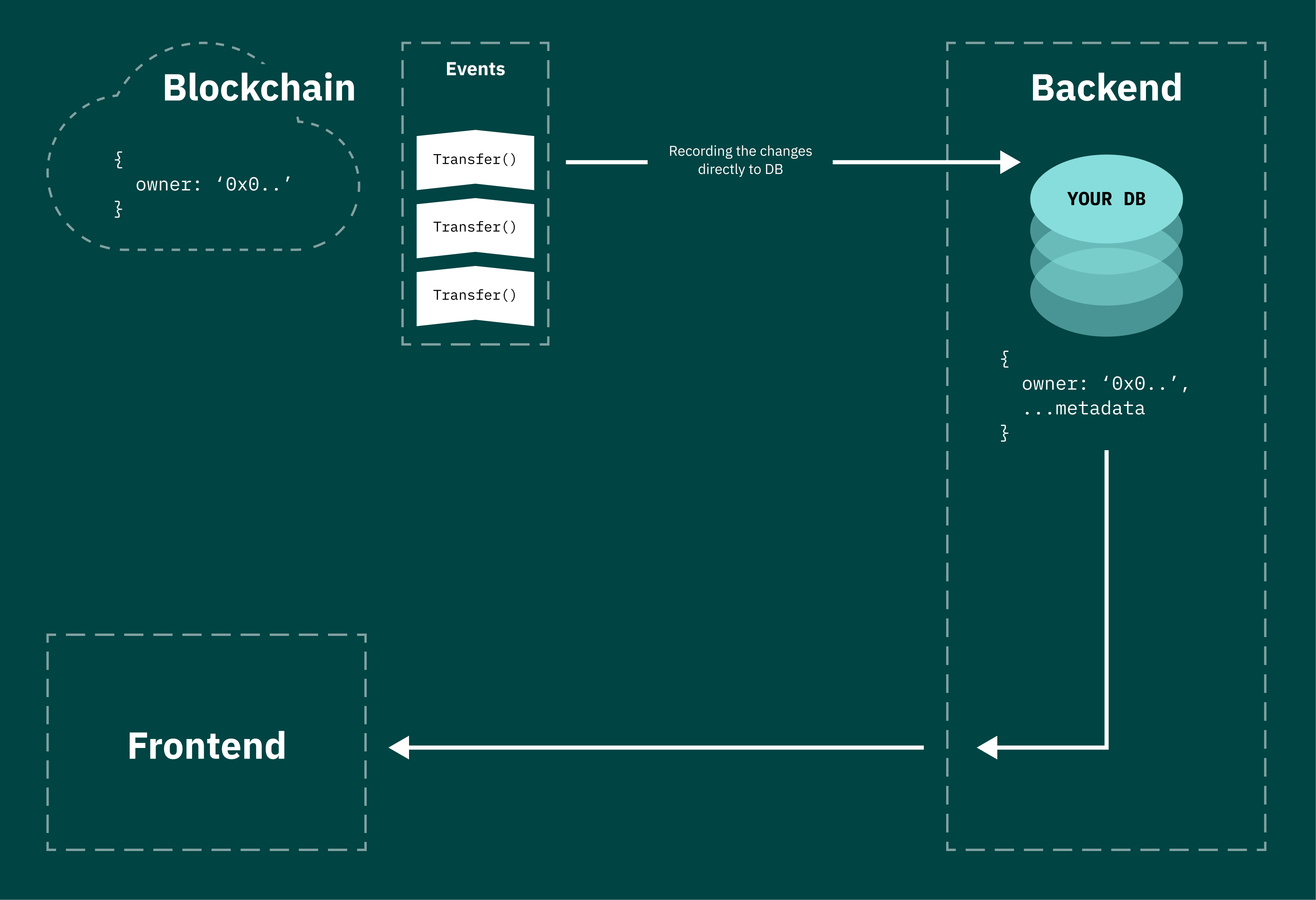
I tried both options during development, and I can say that neither method scales very well. They’re both too “hacky” in general. It’s necessary to somehow abstract from working with RPC and make my database the only source of truth. This can be achieved by catching all on-chain changes to an item (using events) and immediately writing them to the database. This seriously simplifies further development of the dApp.
Some might think, “why not use TheGraph?” In this case, it can only replace RPC requests. It doesn’t solve the fundamental problem — data is still scattered.
So I developed chain-syncer, a module that synchronizes the backend with the blockchain. To install it, use the command:
$ npm i chain-syncer @chainsyncer/mongodb-adapter ethers@^6.0.0
Let’s consider a simple example of using the module. The task is to have the value of the current owner of the item in the database.
// Example using Mongoose
// This is just an abstract example, dont try to copy-paste it
const Mongoose = require('mongoose');
const { ChainSyncer } = require('chain-syncer');
const { MongoDBAdapter } = require('@chainsyncer/mongodb-adapter');
// where will we store the pulled events
await Mongoose.connect(process.env['MONGO_SRV']);
const adapter = new MongoDBAdapter(Mongoose.connection.db);
const syncer = new ChainSyncer(adapter, { /* ... some options ... */ })
syncer.on('Items.Transfer', async (
{ global_index, from_address, block_number, block_timestamp, transaction_hash },
from,
to,
token_id,
) => {
// getting the item by id
const item = await Item.findOne({ _id: token_id });
// updating owner address
item.owner = to;
// saving the item
await item.save();
});
What happens in this piece of code? The module will scan all blocks, starting from the block on which the Items contract is deployed, and pull all the contract events from them. While the scanner is running, the events that have already been drawn will simultaneously go through our handler. As soon as the module pulls up all the old events, it starts tracking new ones. Thus, we get real-time tracking of the owner of each item.
How it works: chain-syncer has 2 loops. The first cycle keeps track of new contract events, and makes sure that there are no duplicates and that no events are missed. The second loop parses the queue of unprocessed events.
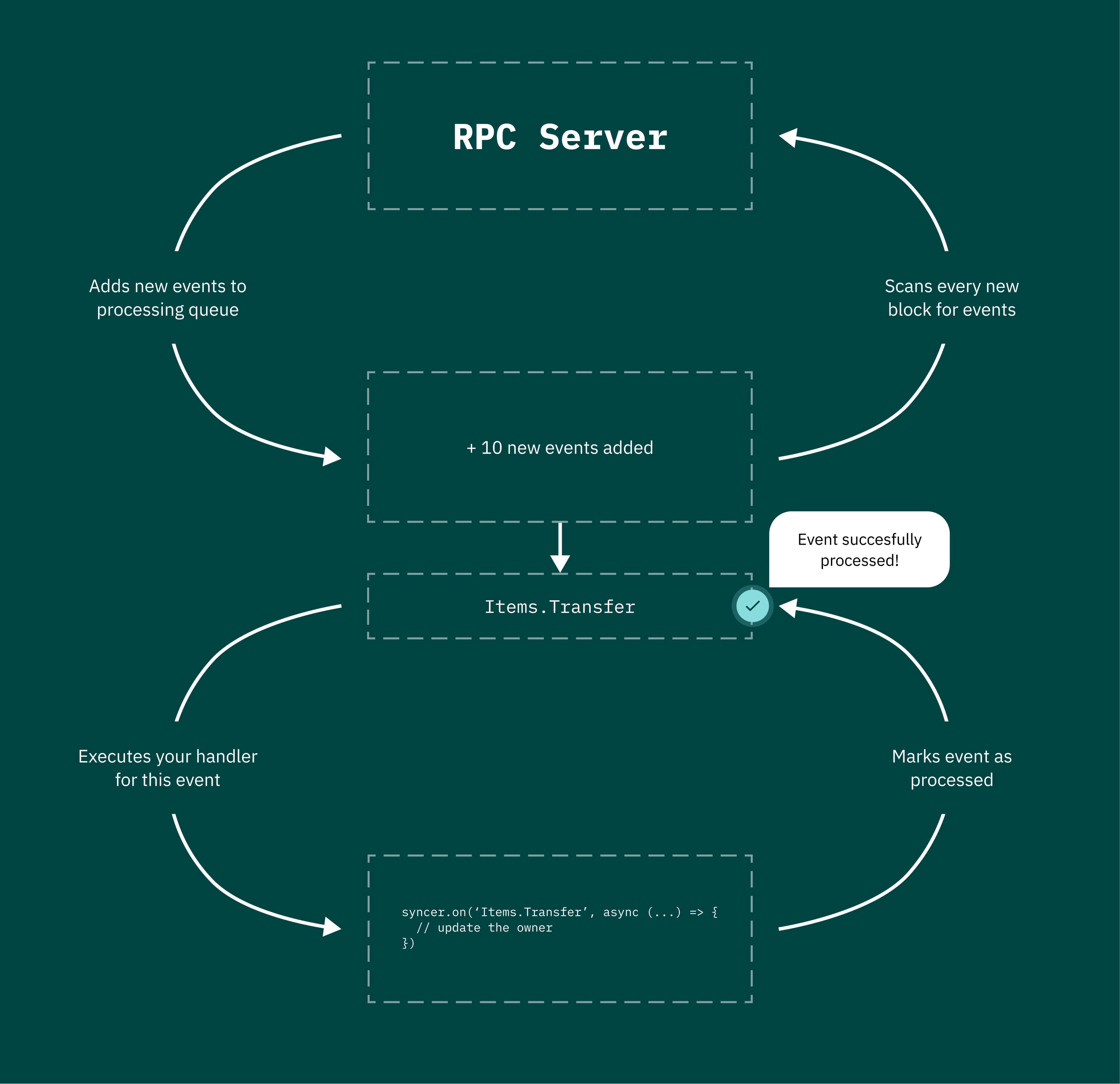
After the event is processed, a flag is placed on it, and it’s sent to the archive.
At the moment, there’s only an adapter for MongoDB. Your developments for a variety of other storages, such as Postgres, MySQL and OracleDB, are widely welcomed. There’s also a module extension in development now (along with the Helm package) that will make the module work similarly to RabbitMQ. This means that it’s convenient to use in a microservice architecture.
In the next article, I’ll write recommendations for working with the module, and why the global_index parameter is needed.
There is still a war going on in Ukraine and at this moment the support of each and everyone is really important. Every dollar strongly brings Ukraine closer to victory 🇺🇦. How can you help.